Hashing Table
Hashing
Hashing adalah teknik yang digunakan untuk menyimpan dan mengambil kunci dengan cepat. Tujuan hashing adalah sebagai metode untuk menyimpan data dalam sebuah array agar penyimpanan data, pencarian data, penambahan datam dan penghapusan data dapat dilakukan dengan cepat.
Hash Table
Hash table adalah salah satu struktur data yang digunakan untuk penyimpanan data sementara. Hash table memori utamanya menggunakan array dengan tambahan algoritma untuk mempercepat dalam memproses data.
Hash
Function
Hash Function adalah suatu fungsi sederhana
untuk mendaoatkan nilai hash dari nilai kunci (key value) dari suatu data.
Ada beberapa hal dalam membuat hash function
antara lain :- Key Value (Nilai yang terdapat pada data(k))
- Ukuran array(table size(m))
- Hash value(Hash index(index yang dituju(h))
- Mid - Square
- Folding
- Division
- Digit Extraction
- Rotating Hash
Mid - Square hashing adalah teknik dimana kunci unik dihasilkan. Dalam teknik ini, nilai benih diambil dan dikuadratkan. Kemudian, beberapa digit dari tengah diekstraksi. Angka-angka yang diekstrak ini membentuk angka yang diambil sebagai benih baru. Teknik ini dapat menghasilkan kunci dengan keacakan tinggi jika nilai benih yang cukup besar diambil. Namun, itu memiliki batasan. Saat bijinya dikuadratkan, jika angka 6-digit diambil, maka persegi akan memiliki 12-digit. Ini melebihi kisaran tipe data int. Jadi, overflow harus diurus. Jika terjadi overflow, gunakan tipe data int panjang atau gunakan string sebagai perkalian jika luapan masih terjadi. Kemungkinan tabrakan di tengah-tengah hashing rendah, tidak usang. Jadi, dalam peluang, jika tabrakan terjadi, itu ditangani menggunakan beberapa peta hash.
Contoh :
Digit mulai posisi 7 sampai 10 (dari kanan) membentuk alamat relatif
Nilai kunci Kunci dipangkatkan Alamat relatif
345237459 119188903096777000 3096
000000472 00000000000222784 0000
890765345 793462899852969000 9852
117400000 13782760000000000 0000
000000472 00000000000222784 0000
890765345 793462899852969000 9852
117400000 13782760000000000 0000
Dari perhitungan terjadi kolisi untuk nomor 000000472 dan 117400000.
Folding
Untuk
mendapatkan alamat relatif, nilai key dibagi menjadi beberapa bagian,
setiap bagian (kecuali bagian terakhir) mempunyai jumlah digit yang sama
dengan alamat relatif. Bagian-bagian ini kemudian dilipat (seperti
kertas) dan dijumlah. Hasilnya, digit yang tertinggi dibuang (bila
diperlukan).
Contoh :
Kunci 123456, 234351, 222456, 321654, dilipat menjadi 2 bagian, setiap 3 digit.
Maka :
123 + 654 = 777 ; simpan 123456 dilokasi 777
234 + 153 = 387 ; simpan 234351 dilokasi 387
222 + 654 = 876 ; simpan 222456 dilokasi 876
321 + 456 = 777; simpan 321654 dilokasi 777
Dari perhitungan terjadi kolisi untuk nomor 123456 dan 321654.
Maka :
123 + 654 = 777 ; simpan 123456 dilokasi 777
234 + 153 = 387 ; simpan 234351 dilokasi 387
222 + 654 = 876 ; simpan 222456 dilokasi 876
321 + 456 = 777; simpan 321654 dilokasi 777
Dari perhitungan terjadi kolisi untuk nomor 123456 dan 321654.
Division
Jumlah lokasi memori yang tersedia dihitung, kemudian jumlah tersebut digunakan sebagai pembagi untuk membagi nilai asli dan menghasilkan sisa. sisa tersebut adalah nilai hashnya. secara umum rumus h(k) = k mod m. Dalam hal ini m adalah jumlah lokasi memori yang tersedia pada array. Fungsi hash tersebut menempatkan record pada kunci K pada suatu memori yang beralamat h(k). Metode ini sering menghasilkan nilai hash yang sama dari dua atau lebih nilai aslinya atau disebut dengan bentrokan. Karena itu, dibutuhkan mekanisme khusus untuk menangani bentrokan yang disebut kebijakan resolusi bentrokan.
Contoh : asumsikan ukuran tabel = 11 dan satu file dengan 8 record menggunakan nilai kunci sebagai berikut : 12, 21, 68, 38, 52, 70, 44, 18.
Maka :
Jumlah lokasi memori yang tersedia dihitung, kemudian jumlah tersebut digunakan sebagai pembagi untuk membagi nilai asli dan menghasilkan sisa. sisa tersebut adalah nilai hashnya. secara umum rumus h(k) = k mod m. Dalam hal ini m adalah jumlah lokasi memori yang tersedia pada array. Fungsi hash tersebut menempatkan record pada kunci K pada suatu memori yang beralamat h(k). Metode ini sering menghasilkan nilai hash yang sama dari dua atau lebih nilai aslinya atau disebut dengan bentrokan. Karena itu, dibutuhkan mekanisme khusus untuk menangani bentrokan yang disebut kebijakan resolusi bentrokan.
Contoh : asumsikan ukuran tabel = 11 dan satu file dengan 8 record menggunakan nilai kunci sebagai berikut : 12, 21, 68, 38, 52, 70, 44, 18.
Maka :
(12 mod 11) + 1 = 1 + 1 = 2 ; simpan 12 dilokasi 2
(21 mod 11) + 1 = 10 + 1 = 11 ; simpan 21 dilokasi 11
(68 mod 11) + 1 = 2 + 1 = 3 ; simpan 68 dilokasi 3
(38 mod 11) + 1 = 5 + 1 = 6 ; simpan 38 dilokasi 6
(52 mod 11) + 1 = 9 + 1 = 10 ; simpan 52 dilokasi 10
(70 mod 11) + 1 = 4 + 1 = 5 ; simpan 70 dilokasi 5
(44 mod 11) + 1 = 0 + 1 = 1 ; simpan 44 dilokasi 1
(18 mod 11) + 1 = 7 + 1 = 8 ; simpan 18 dilokasi 8
Sehingga :
Index 1 2 3 4 5 6 7 8 9 10 11
Nilai Key 44 12 68 – 70 38 – 18 52 – 21
Keunggulan dari ke tiga Teknik Hashing di atas :
- Teknik Division Remainder memberikan penampilan yang terbaik secara keseluruhan.
- Teknik Mid Square dapat dipakai untuk file dengan load factor cukup rendah akan memberikan penampilan baik tetapi kadang-kadang dapat menghasilkan penampilan yang buruk dengan beberapa collision.
- Teknik folding adalah teknik yang paling mudah dalam perhitungan tetapi dapat memberikan hasil yang salah, kecuali panjang nilai key = panjang address.
Digit Extraction
Mendapatkan Hash key dengan cara mengambil digit - digit tertentu dari sebuah string untuk dijadikan hash key nya.
Contoh : Terdapat string 15789, jika kita mengambil digit 1, digit 2, dan digit 4 maka hash keynya adalah 158.
Rotating Hash
Mendapatkan Hash key dengan cara rotasi untuk menggeser digit sehingga menemukan alamat hash key baru.
Contoh : Hash key = 1789
Hasil rotasi = 9871
Trees & Binary Tree
Tree
Merupakan salah satu bentuk struktur data
tidak linear yang menggambarkan hubungan yang bersifat hirarkis
(hubungan one to many) antara elemen-elemen. Tree bisa didefinisikan
sebagai kumpulan simpul/node dengan satu elemen khusus yang disebut Root
dan node lainnya terbagi menjadi himpunan-himpunan yang saling tak
berhubungan satu sama lainnya (disebut subtree). Untuk jelasnya, di
bawah akan diuraikan istilah-istilah umum dalam tree :
- Prodecessor : node yang berada diatas node tertentu.
- Successor : node yang berada di bawah node tertentu.
- Ancestor : seluruh node yang terletak sebelum node tertentu dan terletak pada jalur yang sama.
- Descendant : seluruh node yang terletak sesudah node tertentu dan terletak pada jalur yang sama.
- Parent : predecssor satu level di atas suatu node.
- Child : successor satu level di bawah suatu node.
- Sibling : node-node yang memiliki parent yang sama dengan suatu node.
- Subtree : bagian dari tree yang berupa suatu node beserta descendantnya dan memiliki semua karakteristik dari tree tersebut.
- Size : banyaknya node dalam suatu tree.
- Height : banyaknya tingkatan/level dalam suatu tree.
- Root : satu-satunya node khusus dalam tree yang tak punya predecssor.
- Leaf : node-node dalam tree yang tak memiliki seccessor.
- Degree : banyaknya child yang dimiliki suatu node.
Binary Tree adalah tree dengan syarat bahwa tiap node hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Sesuai dengan definisi tersebut, maka tiap node dalam binary tree hanya boleh memiliki paling banyak dua child.
Operasi-operasi pada Binary Tree :
- Create : Membentuk binary tree baru yang masih kosong.
- Clear : Mengosongkan binary tree yang sudah ada.
- Empty : Function untuk memeriksa apakah binary tree masih kosong.
- Insert : Memasukkan sebuah node ke dalam tree. Ada tiga pilihan insert: sebagai root, left child, atau right child. Khusus insert sebagai root, tree harus dalam keadaan kosong.
- Find : Mencari root, parent, left child, atau right child dari suatu node. (Tree tak boleh kosong)
- Update : Mengubah isi dari node yang ditunjuk oleh pointer current. (Tree tidak boleh kosong)
- Retrieve : Mengetahui isi dari node yang ditunjuk pointer current. (Tree tidak boleh kosong)
- DeleteSub : Menghapus sebuah subtree (node beserta seluruh descendantnya) yang ditunjuk current. Tree tak boleh kosong. Setelah itu pointer current akan berpindah ke parent dari node yang dihapus.
- Characteristic : Mengetahui karakteristik dari suatu tree, yakni : size, height, serta average lengthnya. Tree tidak boleh kosong. (Average Length = [jumlahNodeLvl1*1+jumlahNodeLvl2*2+…+jumlahNodeLvln*n]/Size)
- Traverse : Mengunjungi seluruh node-node pada tree, masing-masing sekali. Hasilnya adalah urutan informasi secara linier yang tersimpan dalam tree. Ada tiga cara traverse : Pre Order, In Order, dan Post Order.
Langkah-Langkahnya Traverse :
- PreOrder : Cetak isi node yang dikunjungi, kunjungi Left Child, kunjungi Right Child.
- InOrder : Kunjungi Left Child, Cetak isi node yang dikunjungi, kunjungi Right Child.
- PostOrder : Kunjungi Left Child, Kunjungi Right Child, cetak isi node yang dikunjungi.
BINARY SEARCH TREES (POHON CARI BINER)
Pohon cari biner adalah pohon biner yang
dirancang untuk menskemakan urutan data yang akan dimasukkan ke dalam
memori agar proses pencarian, penghapusan dan penambahan data dapat
berjalan secara efisien dibanding dengan pemasukan data secara array maupun link.
Sifat dari skema pohon cari biner adalah : (1) setiap elemen yang berada di left substrees selalu lebih kecil dari elemen yang ada di right substrees, (2) setiap elemen yang berada di right substrees selalu lebih besar atau sama dengan elemen yang berada di left substrees.
Contoh : diketahui sekumpulan elemen sebagai berikut :
60, 75, 25, 50, 15, 66, 33, 44
Pembentukan awal skema pohon binernya berturut-turut sebagai berikut :

dan, hasil akhirnya sebagai berikut :
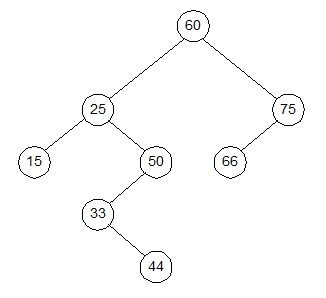
Insert di binary tree mengunakan C
// C++ program to insert element in binary tree
#include <iostream>
#include <queue>
using
namespace
std;
/* A binary tree node has key, pointer to left child
and a pointer to right child */
struct
Node {
int key;
struct Node*
left, *right;
};
/* function to create a new node of tree and r
eturns pointer */
struct
Node* newNode(int key)
{
struct Node* temp
= new Node;
temp->key = key;
temp->left = temp->right =
NULL;
return temp;
};
/* Inorder traversal of a binary tree*/
void
inorder(struct Node* temp)
{
if (!temp)
return;
inorder(temp->left);
cout << temp->key <<
" ";
inorder(temp->right);
}
/*function to insert element in binary tree */
void
insert(struct Node* temp, int key)
{
queue<struct Node*>
q;
q.push(temp);
// Do level order traversal until we
find
// an empty place.
while (!q.empty())
{
struct Node* temp
= q.front();
q.pop();
if (!temp->left)
{
temp->left
= newNode(key);
break;
} else
q.push(temp->left);
if (!temp->right)
{
temp->right
= newNode(key);
break;
} else
q.push(temp->right);
}
}
// Driver code
int
main()
{
struct Node* root
= newNode(10);
root->left = newNode(11);
root->left->left = newNode(7);
root->right = newNode(9);
root->right->left =
newNode(15);
root->right->right =
newNode(8);
cout << "Inorder
traversal before insertion:";
inorder(root);
int key = 12;
insert(root, key);
cout << endl;
cout << "Inorder
traversal after insertion:";
inorder(root);
return 0;
}
Deletion di binary tree
// C++ program to delete element in binary tree
#include <bits/stdc++.h>
using
namespace
std;
/* A binary tree node has key, pointer to left
child and a pointer to right child */
struct
Node {
int key;
struct Node
*left, *right;
};
/* function to create a new node of tree and
return pointer */
struct
Node* newNode(int key)
{
struct Node* temp
= new Node;
temp->key = key;
temp->left = temp->right =
NULL;
return temp;
};
/* Inorder traversal of a binary tree*/
void
inorder(struct Node* temp)
{
if (!temp)
return;
inorder(temp->left);
cout << temp->key <<
" ";
inorder(temp->right);
}
/* function to delete the given deepest node
(d_node) in binary tree */
void
deletDeepest(struct Node* root,
struct Node*
d_node)
{
queue<struct Node*>
q;
q.push(root);
// Do level order traversal until
last node
struct Node*
temp;
while (!q.empty())
{
temp =
q.front();
q.pop();
if (temp ==
d_node) {
temp
= NULL;
delete (d_node);
return;
}
if (temp->right)
{
if (temp->right
== d_node) {
temp->right
= NULL;
delete (d_node);
return;
}
else
q.push(temp->right);
}
if (temp->left)
{
if (temp->left
== d_node) {
temp->left
= NULL;
delete (d_node);
return;
}
else
q.push(temp->left);
}
}
}
/* function to delete element in binary tree */
Node* deletion(struct Node* root, int key)
{
if (root ==
NULL)
return NULL;
if (root->left
== NULL && root->right == NULL) {
if (root->key
== key)
return NULL;
else
return root;
}
queue<struct Node*>
q;
q.push(root);
struct Node*
temp;
struct Node* key_node
= NULL;
// Do level order traversal to find
deepest
// node(temp) and node to be deleted
(key_node)
while (!q.empty())
{
temp =
q.front();
q.pop();
if (temp->key
== key)
key_node
= temp;
if (temp->left)
q.push(temp->left);
if (temp->right)
q.push(temp->right);
}
if (key_node
!= NULL) {
int x =
temp->key;
deletDeepest(root,
temp);
key_node->key
= x;
}
return root;
}
// Driver code
int
main()
{
struct Node* root
= newNode(10);
root->left = newNode(11);
root->left->left = newNode(7);
root->left->right =
newNode(12);
root->right = newNode(9);
root->right->left =
newNode(15);
root->right->right =
newNode(8);
cout << "Inorder
traversal before deletion : ";
inorder(root);
int key = 11;
root = deletion(root, key);
cout << endl;
cout << "Inorder
traversal after deletion : ";
inorder(root);
return 0;
}
Sumber :
https://www.geeksforgeeks.org/mid-square-hashing/
https://www.geeksforgeeks.org/deletion-binary-tree/
https://saragusti22.wordpress.com/2015/05/04/pengantar-struktur-data-tree-dan-binary-tree/


Tidak ada komentar:
Posting Komentar